

.png)
This article is based on a recent webinar which you can rewatch below. It dives into the various considerations when setting up an business-wide data & AI literacy assessment, or working with a partner to help achieve this. Benchmarking is essential if you're starting or continuing to invest in your data culture. Yet most organisations will not take the time to assess where they are at before spending the big bucks. And that leads to the same old cycle of struggling to prove value.
Key takeaways
- Most data literacy assessments are designed around the top of the capability curve, they miss the confidence and mindset gaps that actually explain why data programmes stall
- The Dunning-Krueger effect hits data harder than almost any other discipline. Self-reported scores routinely overstate reality, which is why behaviour-based questions ("have you used it?") produce more reliable insight than perception-based ones ("can you use it?")
- Anonymisation isn't a nice-to-have, without it, social desirability bias skews your results before the analysis starts
- Expect your respondents to already be your most data-engaged people. The silent majority who most need developing are the least likely to complete the assessment
- Keep assessments to 20–30 questions and protect that number. Enterprise stakeholders will expand it to 80 if you let them, and completion rates will collapse
- The output only has value if it feeds directly into action, like a learning plan, a hiring decision or a programme design. A score in isolation tells you almost nothing
- Lead data & AI literacy programmes with value and relevance, not governance. Governance is the referee's rulebook, but people need to care about the game before they'll apply the rules
Most organisations that invest in data & AI literacy assessments do it backwards. They audit infrastructure, check what tools are in place, survey senior stakeholders, and then wonder why the results don't translate into meaningful change.
Greg Freeman, CEO of Data Literacy Academy, puts it bluntly: "Everyone in this room knows there's a data people problem. The assessment is just the evidence to show that to the rest of the business."
So if the insight is already there, what's the point of a formal assessment? And if you're going to run one, why do most of them fail to move anything?

The Gartner definition only tells half the story
The industry standard definition of data literacy, Gartner's "ability to read, write, and communicate data in context", was clearly written by a data professional for data professionals. It describes the ceiling, not the floor.
The problem is that the vast majority of an organisation's workforce isn't anywhere near that ceiling. Research consistently points to 80%+ of employees operating well below what even "ground zero" looks like on the Gartner scale. And yet assessment frameworks keep being designed around the top of the curve.
What's missing from that definition is the layer beneath it: confidence and mindset. Whether someone wakes up and instinctively sees their business problems as data problems. Whether they feel safe enough to ask a question in a data conversation without feeling like the room is judging them. Whether they even think data is their job at all.
"There's no point understanding data if you don't actually think of how it's going to help your business problems," says Freeman. An assessment that only measures hard skills will miss the actual reason most data programmes stall.

The Dunning-Krueger problem is bigger in data than anywhere else
Ask your finance team if they're data literate. Most of them will look at you as if the question barely makes sense. They've spent their careers in Excel, working with numbers and metrics. Of course they're data literate.
But that's not necessarily true, and they don't know what they don't know.
This is often the Dunning-Krueger effect in action, the less someone understands a subject, the more competent they perceive themselves to be. And according to Freeman, data is the most severe example of this phenomenon he's encountered in his career: "True data fluency is a country mile away from what most finance professionals think they already have."
The practical consequence for assessments is significant. If you ask people to self-rate their data confidence or capability, you'll get scores that overstate reality. This isn't because people are dishonest, but because their reference point is their own experience of data, which they naturally assume represents data as a whole.
This is why Ant Burton, VP of Product and Strategy at Data Literacy Academy, argues that behaviour-based questions outperform perception-based ones: "It's not 'can you access this data?'. It's 'have you, and how often?' Those are very different questions."
The dashboard exists in Power BI. The user has theoretically logged in. But have they actually used it to inform a decision that has moved the needle? Those are the questions leaders need to be asking before they assume that adoption rates mean successful outcomes.
What anonymisation actually does
There's a specific psychological concept at stake when you strip names from assessments: social desirability bias. People tell you what they think you want to hear when their name is attached to the answer, particularly when they suspect the results might affect how they're perceived.
This is especially pronounced in face-to-face assessments, where a third party sits across from someone and asks how data-confident they are. The honest answer "I find it intimidating and I avoid it where I can", becomes rarer to hear in that setting ..
Burton frames it around creating safe spaces: "A fear of asking the wrong question is a real barrier. People don't like feeling stupid, but they want to know more and they want to do better." Anonymisation is what gives that silent majority, or what we often call the data-disengaged 80%, permission to answer honestly.
Without it, your results are skewed before the analysis even begins.
The sampling problem nobody talks about
Even with full anonymisation, a data & AI literacy assessment has a structural bias baked in that most CDOs underestimate.
When an email lands in 10,000 inboxes with the subject line "Data & AI Literacy Assessment," the people who open it, engage with it, and complete it are disproportionately the ones who already have a relationship with data. The genuinely disengaged majority, the people who think "data is not a me thing, there's a team for that", will delete it or ignore it within seconds.
"The people who respond will be the ones who are already better at data than the ones who don't," says Freeman. "That same silent majority you're worried about in your business is the same group that won't touch your assessment."
This doesn't make the assessment worthless. It makes the framing of results critical. If you're building a business case from assessment data, the reality is likely worse than what you're reporting, and that needs to be part of the narrative you present upwards.
The implication: executive communication before the assessment goes out isn't optional. Senior leaders need to actively champion completion, particularly amongst the teams least likely to engage, or you'll end up only measuring the people who already will do better in the first place, leaving a black hole in your analysis.
The length problem is where most internal builds fall apart
Twenty to thirty structured questions. That's the range that produces meaningful insight without losing respondents halfway through.
In practice, organisations routinely blow past this. The instinct in enterprise settings is inclusion: let each department add their questions, collect all the perspectives, make everyone feel heard. What starts as 15 questions becomes 80 by the time stakeholders have finished adding theirs.
Freeman describes the test simply: "If you were sent a marketing assessment with 150 questions in it, would you answer them? You'd open it and say 'Absolutely not.'"
For people who don't see data as their job, which is most of your organisation, the friction of a long survey is enough to abandon it. The discipline required here is resisting the internal pressure to be too comprehensive. Keep the question set to what you actually need to know, and protect it from well-intentioned additions.
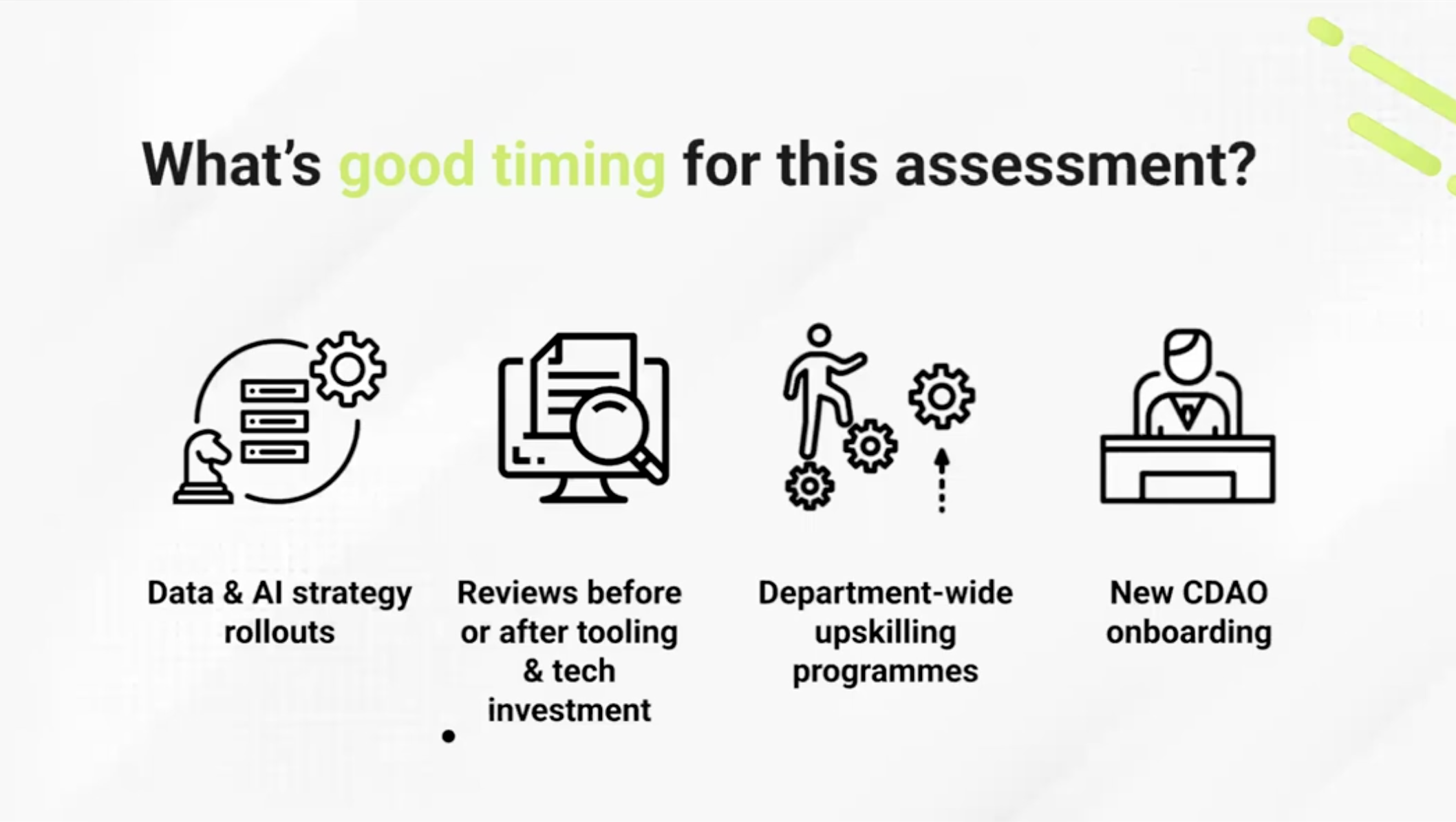
Timing: When to run one
The best timing Freeman has seen: when a new CDO or CDAO joins the business.
The intuition is usually already there, that data maturity is low and the people problem is real. But intuition doesn't build a business case. An assessment run in the first weeks of a new appointment creates a baseline that can anchor the entire programme strategy, and it does so before political capital has been spent arguing for investment.
The other natural trigger is technology deployment. Data & AI literacy obviously drives adoption. If you're rolling out new data products into a department and nobody's assessed where people actually are, you're making investment decisions blind. Burton puts it directly: "Capability without confidence, and access without clarity, doesn't actually drive change."
A data warehouse doesn't make people data-driven. Neither does a Power BI or Tableau licence. What the assessment surfaces is whether the people receiving those tools are remotely ready to use them.
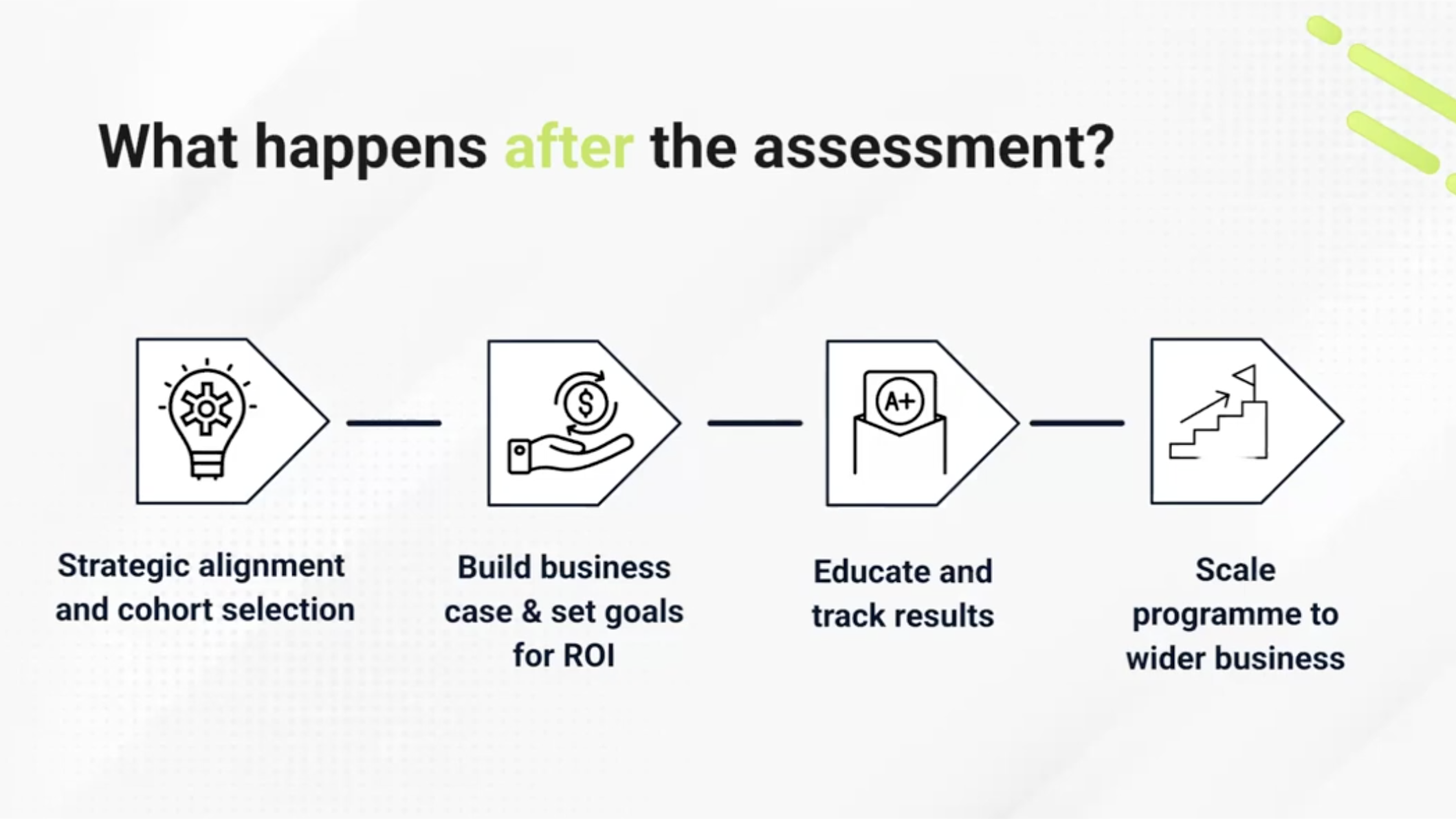
What the output should actually tell you
A score alone is close to useless. The organisations that extract value from assessments use the output to answer a specific set of questions:
- Where are the behavioural gaps, not just the capability gaps?
- Which teams are underestimating their problems?
- Where is low confidence a tooling issue versus a cultural one?
- Which cohorts are strategically valuable enough to prioritise?
That last question is the bridge from assessment to programme. Burton describes it as identifying "key strategic cohorts", groups whose data capability is tied directly to a live business priority. A marketing team running a digital conversion transformation, for example, is a far more compelling investment case than a general population rollout, and assessment data showing their literacy levels are below average makes the argument concrete rather than instinctive.

"This isn't data for data's sake," says Freeman. "It's how are we going to use these insights to go somewhere specific."
The worst outcome, and one that's more common than it should be, is a report that sits on a shared drive and generates no action. If the assessment isn't feeding directly into a learning plan, a hiring decision, or a programme design, it wasn't worth doing.
One more thing on governance
So, what should actually be in a data & AI literacy programme?
Data catalogues, governance training, MDM, these have their place, but they're a terrible front door. They're the stick, not the carrot. And leading with them is why programmes get reset in year two.
Freeman uses a football analogy to explain why: if you already love the game, you'll referee it properly because you understand what's at stake. If you don't see the value in it, you'll get through the ninety minutes as painlessly as possible and apply none of the rules. "A lot of the time we ask business people to referee data when we've never told them what the value is."
Change management and hearts-and-minds messaging come first. How does data make someone's job easier? What decisions does it help them get right that they're currently getting wrong? Once those questions are answered, you've earned the right to talk about governance.
Not before.
Watch the full webinar
Related blog posts
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)

.png)

Unlock the power of your data & AI
Speak with us to learn how you can embed org-wide data & AI fluency today.

